C’est un projet de lab. Une seule VM, un VNet, quelques règles réseau. Rien de spectaculaire sur le papier. Mais j’ai choisi de le faire “comme en prod” : backend tfstate chiffré sur Azure Storage, Service Principal RBAC, secrets dans un Key Vault, Managed Identity pour éviter de stocker des credentials sur la machine. C’est ce choix qui a rendu le projet intéressant.
L’idée de départ était simple : comprendre Terraform avant d’en avoir besoin dans un contexte professionnel. Pas en regardant des tutoriels, en faisant.
L’approche déclarative, c’est quoi concrètement
Terraform, c’est du code déclaratif. On décrit l’état qu’on veut, pas les étapes pour y arriver. On écrit “je veux un VNet avec ce CIDR dans cette région” et Terraform calcule ce qu’il faut créer, modifier ou détruire pour atteindre cet état.
J’ai un background de douze ans en BI et Data, et ce paradigme m’a rappelé quelque chose. En Power BI, on décrit un modèle de données, des relations, des mesures DAX. On ne code pas les requêtes SQL sous-jacentes, on décrit ce qu’on veut obtenir. Le moteur fait le reste. C’est la même logique : Terraform est le moteur, le HCL est la description de l’état cible.
Ce qui change concrètement : on ne se demande plus “comment créer ce VNet via l’API Azure”, on se demande “quel état je veux pour mon réseau”. C’est une façon différente de penser l’infrastructure. Pas forcément plus simple au départ, mais beaucoup plus solide à tenir dans la durée.
La structure qui force à réfléchir avant d’agir
Un projet Terraform minimal, c’est quatre fichiers. providers.tf pour déclarer avec quel cloud on travaille. variables.tf pour les paramètres. outputs.tf pour les valeurs qu’on veut récupérer après déploiement. Et main.tf pour les ressources.
Ce découpage n’est pas anodin. Séparer la déclaration des variables de leurs valeurs réelles force à distinguer ce qui peut être commité de ce qui ne peut pas l’être. Mon IP source SSH n’a rien à faire sur GitHub. Ce réflexe, en BI, c’est la différence entre un rapport Power BI et les données qu’il consomme. Le rapport est versionnable, les données non.
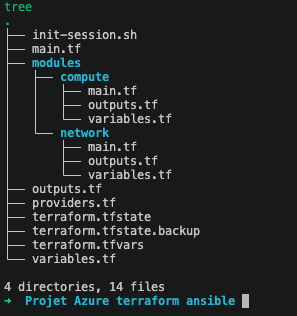
Quand le projet a grossi, j’ai découpé main.tf en modules locaux : un module network pour tout ce qui est réseau (VNet, Subnet, NSG, NIC), un module compute pour la VM et sa Managed Identity. Le main.tf racine est passé de 113 lignes à 30 lignes d’orchestration pure. Il ne crée plus rien directement, il appelle des modules et fait circuler les valeurs.
Les modules sont des boîtes opaques qui ne se parlent pas directement : tout transite par la racine via des inputs et des outputs. Comme une fonction Python ou une CTE en SQL.
La sécurité n’était pas un ajout de fin de projet
J’aurais pu déployer une VM avec Terraform en deux heures, en stockant mes credentials dans un fichier .tfvars et en gardant le state en local. Ça aurait marché. Mais j’ai voulu construire l’architecture de sécurité couche par couche, et c’est là que le projet a pris de l’épaisseur.
Le backend tfstate distant d’abord. Le state Terraform contient les attributs de toutes les ressources, parfois des secrets. Le laisser en local sur le Mac, c’est un risque : pas de verrou d’accès concurrent, pas de chiffrement, pas de traçabilité. Un Azure Storage Account avec state locking via blob lease, c’est la version minimale acceptable.
Ensuite un Service Principal dédié avec le rôle Contributor, au lieu de lancer Terraform avec mon compte Owner. Terraform n’a pas besoin d’être Owner pour créer des ressources.
Le Key Vault pour stocker le secret du SP. Jamais en clair dans un fichier, jamais dans une variable d’environnement hardcodée quelque part. Un script init-session.sh récupère le secret au démarrage de session et l’exporte en mémoire terminal uniquement.
Et la Managed Identity sur la VM. La VM lit le Key Vault sans avoir de credentials stockés nulle part sur elle. Azure gère le cycle de vie du token. C’est le pattern décrit dans les benchmarks CIS Azure et les recommandations ANSSI : pas de secrets statiques sur les ressources.
Ce que j’ai retenu de cette séquence : ces contrôles ne s’intègrent pas après coup. Un Key Vault ajouté sur une architecture existante, c’est douloureux. Prévu dès le départ, ça se pose naturellement. La sécurité n’est pas une couche, c’est une contrainte de conception.
J’ai autant appris Azure que Terraform
Ce n’était pas prévu. J’ai passé presque autant de temps à comprendre Azure qu’à comprendre Terraform.
Le SKU Basic des IP publiques retiré pour les nouveaux abonnements. La taille Standard_B1s indisponible en westeurope. La différence entre Contributor et User Access Administrator que j’ai découverte en cherchant pourquoi mon SP n’arrivait pas à créer des azurerm_role_assignment. Le comportement de set -euo pipefail dans un script sourcé qui tuait mon terminal zsh à chaque session.
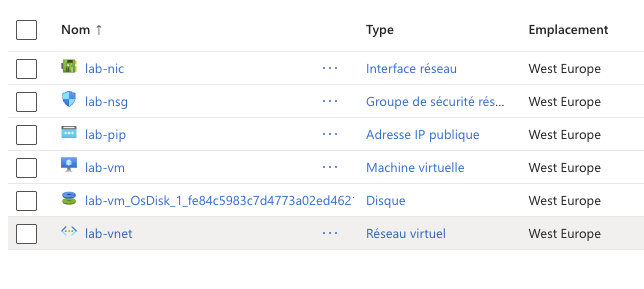
Ces blocages n’étaient pas dans la documentation Terraform. Ils étaient dans la réalité Azure. Et c’est là que le portail reste utile. Pas pour déployer, mais pour vérifier, inspecter, comprendre ce qui se passe vraiment. Terraform déploie l’infrastructure, le portail permet de la lire.
Ce que Terraform ne remplace pas
Terraform décrit un état cible. Il ne peut pas tout automatiser pour autant.
L’infrastructure de pilotage, je l’ai créée à la main via Azure CLI : le Storage Account pour le backend tfstate, le Key Vault. Ces ressources sont persistantes entre les sessions et ne peuvent pas être dans le state Terraform qu’elles sont censées héberger. C’est le problème de bootstrap de l’IaC : il faut bien commencer quelque part hors du système.
Et la connaissance du provider reste nécessaire. Terraform sans Azure, c’est comme DAX sans comprendre les relations dans un modèle tabulaire. On peut copier des formules, ça fonctionnera jusqu’au moment où ça ne fonctionnera plus. Sans le fond, on est bloqué et on ne sait même pas pourquoi.
La suite
Le projet continue avec Ansible pour la configuration post-déploiement : durcissement SSH, fail2ban, UFW, potentiellement un agent Wazuh pour remonter les logs vers le SIEM du homelab. Terraform crée l’infrastructure, Ansible configure ce qui tourne dessus. Les deux outils sont complémentaires, pas substituables.
Les fichiers de configuration sont sur GitHub.
Ce que je retiens
Ce projet m’a confirmé quelque chose que j’avais déjà vu du côté BI : la qualité d’une architecture se mesure avant qu’une seule ligne de code soit écrite. En Data, les projets qui finissent mal ont presque toujours les mêmes symptômes : modèle pensé après coup, gouvernance des accès ajoutée en urgence, pas de séparation entre environnements. En IaC, c’est la même chose avec d’autres noms.
Terraform force à poser ces questions tôt parce que le code est le seul endroit où l’architecture existe. Il n’y a pas d’interface graphique pour masquer les choix. Tout est lisible, tout est versionnable. Ça met mal à l’aise quand les choix sont discutables. C’est pour ça que j’ai trouvé l’exercice utile.
Je ne suis pas sûr que tous mes choix étaient les bons. Le SP scopé à la subscription entière plutôt qu’au Resource Group, c’est une concession au fait que le RG est éphémère dans ce lab. En production, ce serait inacceptable. Mais documenter ces arbitrages fait partie du travail : un code qu’on ne peut pas expliquer n’est pas du code qu’on contrôle.