Un proxy DLP devant mon LLM local
Ça a commencé par un article lu un soir : les RSSI s’inquiètent de voir des secrets (clés API, tokens) partir dans les prompts envoyés aux modèles de langage. Le constat qui m’a accroché, c’est que le problème n’est pas le modèle. C’est le périmètre de confiance autour de lui. Une clé collée par erreur dans un prompt traverse une frontière, et selon où passe cette frontière, on récupère la trace ou pas.
J’ai voulu me prouver le truc chez moi avant d’en parler en entretien. Ce billet est le premier d’une série où je construis, étage par étage, un mini système de management de la sécurité orienté IA dans mon homelab. L’étage de ce billet, c’est le contrôle technique minimal : un proxy qui inspecte les prompts et caviarde les secrets avant qu’ils n’atteignent le LLM. Le code est sur GitHub (Kurgran/Homelab, dossier IA-Zone-Confiance/proxy/).
Pourquoi un proxy, et pas juste “faire attention”
Faire attention ne tient pas comme contrôle. L’erreur humaine arrive, surtout quand on bricole un agent à 23h. Il faut un point de passage obligatoire entre celui qui écrit le prompt et le modèle qui le reçoit. C’est le rôle d’un proxy IA, parfois appelé AI gateway : un programme classique (pas un modèle) qui s’intercale, lit le trafic, le filtre, le transforme et le journalise.
Le concept qui structure tout, c’est la frontière de confiance : la limite au-delà de laquelle je ne maîtrise plus ce qui arrive à mes données. Avec un LLM local sous Ollama, cette frontière, c’est mon VLAN. Si un secret fuite, il atterrit dans mes logs, chez moi, et je peux nettoyer. Avec un LLM cloud, la frontière, c’est la passerelle Internet : une fois le prompt parti, il est journalisé chez le fournisseur, hors de mon contrôle, et seule la révocation de la clé reste possible. La leçon est la même dans les deux cas : le masquage doit se produire avant le franchissement de la frontière, jamais après.
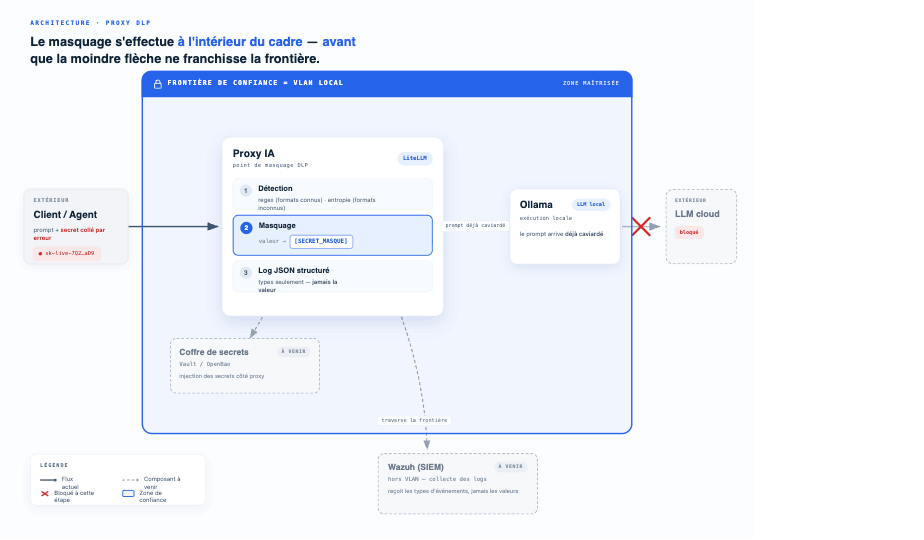
La frontière de confiance, c’est le VLAN. Le masquage se fait à l’intérieur, avant que le prompt n’atteigne le modèle. Coffre, SIEM et backend cloud viendront dans les versions suivantes.
Le choix technique : LiteLLM, un hook pre_call, et detect-secrets
J’ai retenu LiteLLM comme proxy. Il parle l’API d’OpenAI (donc n’importe quel client compatible se branche dessus sans réécriture), il route vers plusieurs backends, et surtout il expose un système de garde-fous avec des hooks pre_call, during_call et post_call. Le pre_call est exactement le bon point d’ancrage : il s’exécute avant le routage vers le backend. Si je masque là, je masque avant la frontière. Ce n’est pas un détail de plomberie, c’est la garantie d’architecture qui rend le contrôle valable.
Pour la détection, j’ai regardé les outils tout faits avant de coder. LLM Guard a un scanner de secrets, mais c’est en réalité un fork de detect-secrets, et il tire torch et transformers dans l’image : trop lourd pour ce que je veux. Presidio, lui, est taillé pour le PII (noms, emails, IBAN via reconnaissance d’entités) et faible sur les clés API. La page de conception de mon projet les listait comme équivalents, c’était une erreur que j’ai corrigée : pour des secrets, ce n’est ni l’un ni l’autre. J’ai donc écrit un garde-fou maison qui importe detect-secrets directement. Tout vit dans un seul conteneur, un seul process Python : LiteLLM, mon garde-fou et la lib de détection.
|
|
Le default_on: true compte autant que le mode. Un contrôle qu’on peut activer requête par requête est un contrôle qu’on oublie d’activer. Là, il s’applique partout, par défaut.
Détecter : deux méthodes opposées, qu’il vaut mieux séparer
C’est ici que le projet a cessé d’être un tuto pour devenir un vrai sujet de conception. detect-secrets détecte de deux façons : des expressions régulières pour les formats connus (une clé AWS a une structure reconnaissable), et une analyse d’entropie pour les chaînes anormalement aléatoires, censée attraper les secrets de format inconnu.
Mon premier réflexe a été d’utiliser la fonction de scan toute prête de la lib. Mauvaise idée. En testant un prompt parfaitement légitime (“explique la différence entre TCP et UDP”), j’ai vu le garde-fou flaguer TCP, et, la, des bouts de mots. La fonction de scan force un mode “eager” qui court-circuite le filtre de longueur et de seuil de l’entropie : chaque mot passe à la moulinette, et le bruit explose. Le détecteur regex, lui, restait chirurgical : il avait chopé la fausse clé AWS, et seulement elle.
Le point intéressant, ce n’est pas le bug, c’est la nature de la correction. La tentation était de bidouiller un seuil. La vraie réponse était architecturale : faire tourner les deux méthodes comme deux passes distinctes et spécialisées, puis fusionner les résultats. Le regex s’occupe des formats connus. Une passe d’entropie maison s’occupe des formats inconnus, avec ses propres garde-fous (je ne garde un token que s’il dépasse 20 caractères et un seuil d’entropie de Shannon de 4,5). Deux contrôles qui font chacun leur travail valent mieux qu’un seul scan indifférencié qui mélange tout. Regex pour le connu, entropie pour l’inconnu.
Masquer : remplacer la valeur, pas sa position
Une fois le secret détecté, il faut le caviarder dans le prompt. Deux routes : remplacer par position (les colonnes début/fin du secret dans le texte) ou remplacer par valeur (chercher la chaîne et la substituer partout). J’ai pris la valeur.
La détection me donne déjà la valeur du secret, pas ses colonnes. Et un remplacement par valeur est insensible aux décalages : dès qu’on masque un premier secret, tous les index qui suivent bougent, et un code basé sur les positions se met à corrompre le texte. J’ai assez vu, en SQL et en VBA, des traitements basés sur des indices de colonne casser au premier décalage pour me méfier des positions mobiles. Le sens d’échec est rassurant : au pire je sur-masque, jamais je ne sous-masque.
|
|
Le jeton de remplacement est court et de basse entropie, sans format reconnaissable : il ne sera jamais re-flaggé par mes propres passes.
L’invariant : masquer avant de journaliser
Voilà la règle que je me suis imposée et qui ne bouge pas : le masquage précède la journalisation. Sinon, en voulant tracer l’incident, je recopie le secret en clair dans mes logs, et la fuite est juste déplacée vers le SIEM. Le log ne reçoit que le type du secret (“AWS Access Key”) et le compte, jamais la valeur. La forme finale, c’est un événement JSON structuré, pensé pour être relu plus tard par un dashboard et par Wazuh :
|
|
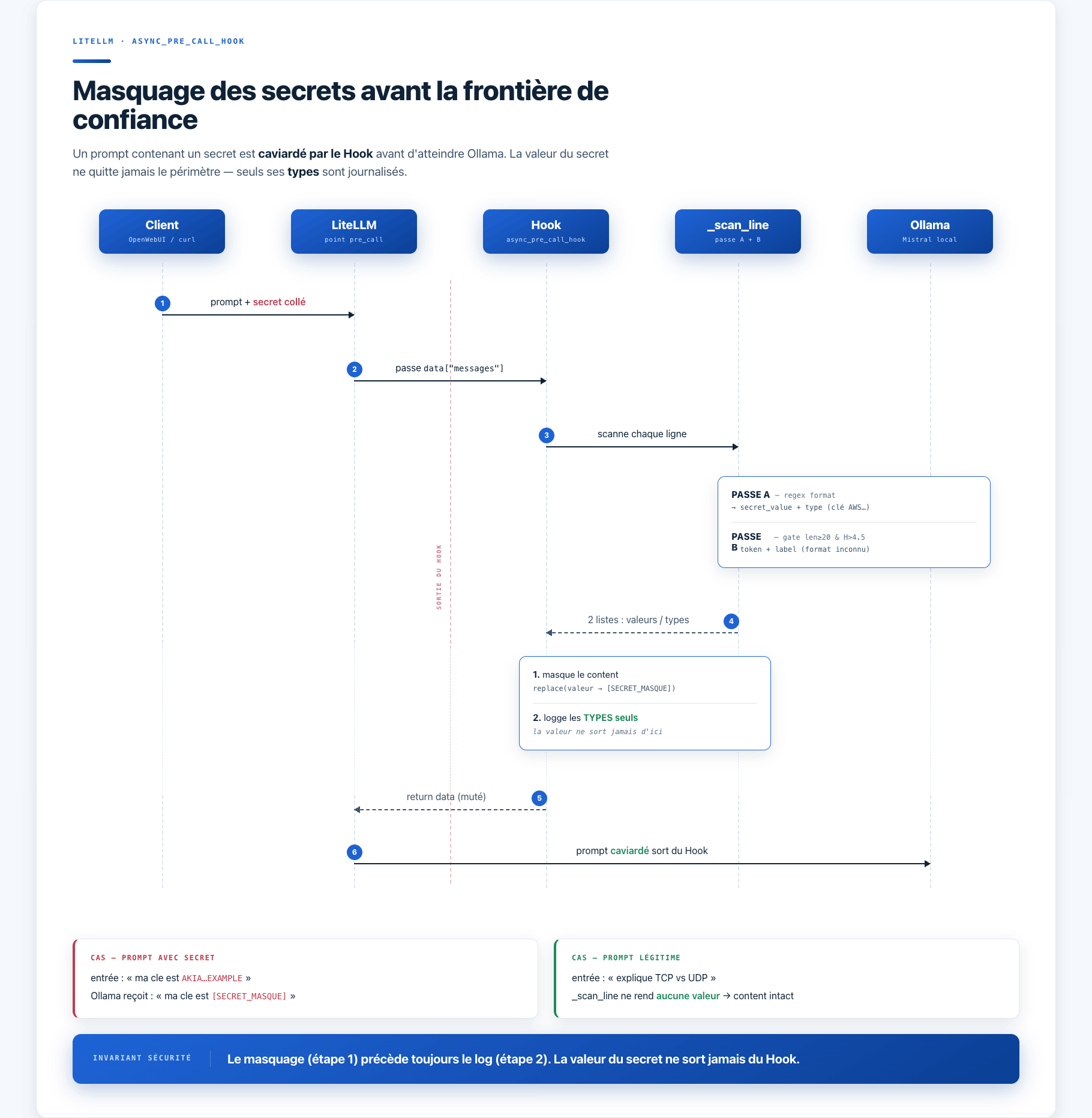
La mécanique interne du hook : détection (passes regex et entropie), masquage, puis log des types seuls. La valeur du secret ne quitte jamais le hook.
Dans le code, détecter puis masquer est une contrainte logique (il faut avoir détecté pour masquer). Mais masquer puis logger n’est pas une contrainte technique : rien n’empêcherait de logger le contenu brut juste après la détection. C’est un choix de sécurité que j’impose. Et le vrai verrou, ce n’est même pas l’ordre des opérations, c’est que l’événement de log ne référence physiquement que deux listes, les types et le compte, jamais les valeurs. L’ordre énonce le principe. La séparation des listes en est la garantie structurelle. Les deux ensemble, c’est de la défense en profondeur, dans le code cette fois.
Un mot d’honnêteté sur le revers de la médaille : ce proxy est l’actif le plus sensible de l’installation, puisqu’il voit tout le trafic en clair avant masquage. Pour un banc d’essai sur mon VLAN principal, je l’assume, mais c’est une dette à documenter. La cible reste un VLAN dédié et durci.
Le projet, lu à travers deux normes ISO
J’étudie en parallèle ISO/IEC 27001 (le management de la sécurité de l’information) et ISO/IEC 42001 (le management de l’IA, publiée fin 2023), et je garde les deux perspectives sur chaque brique que je monte. Ce proxy se lit dans les deux.
Côté 27001, c’est un contrôle de sécurité classique : la fonction DLP répond au contrôle de prévention des fuites de données (Annexe A, version 2022), et mon invariant “masquer avant de journaliser” prolonge la discipline attendue par le contrôle de journalisation. La logique exigence, contrôle, preuve est celle d’un SMSI.
Côté 42001, la même brique devient de la gouvernance de l’IA : je traite l’usage du LLM comme un système d’IA géré, avec une frontière de confiance explicite et une traçabilité des flux. C’est ce qui prépare le registre IA des versions suivantes.
Rien n’est certifié ici, c’est un homelab. Mais tenir les deux lectures ensemble, sécurité de l’information et gouvernance de l’IA, c’est la posture que je veux ancrer.
La preuve, et une surprise sur la latence
Tests en conteneur, deux cas. Une fausse clé AWS dans le prompt : elle ressort [SECRET_MASQUE] côté Ollama, le log émet l’événement JSON avec le bon type, et la valeur n’apparaît en clair nulle part (LiteLLM caviarde aussi le corps brut dans ses propres dumps, ça fait une double protection). Un prompt légitime : il passe intact, aucun faux événement. Les deux moitiés du critère sont tenues.

Les logs du proxy : l’événement JSON sur la fausse clé AWS (le type seul, jamais la valeur), et le prompt légitime qui passe sans bruit.
La surprise est venue des temps de réponse. En attribuant la latence sur les logs, le contrôle DLP s’exécute en moins d’une seconde. Les 14 puis 39 secondes que je voyais venaient entièrement de la génération du modèle Mistral, à un débit constant d’environ 16 à 17 tokens par seconde, donc linéaire dans le nombre de tokens produits. Conclusion utile : le filet de sécurité est gratuit en latence. Personne ne pourra justifier de le couper pour des raisons de performance.
La suite
La V2 est déjà cadrée : ajouter un backend cloud derrière le même proxy et envoyer le même prompt empoisonné aux deux destinations. C’est là que la comparaison des frontières devient démontrable, proxy coupé contre proxy actif, local contre cloud. Ce sera le billet suivant de la série.
Ce que j’en retiens
Le geste technique de ce projet est petit : une centaine de lignes de Python dans un hook. Ce qui m’a occupé, ce sont les décisions autour. Séparer deux méthodes de détection au lieu de les empiler. Choisir le masquage par valeur pour un code qui ne casse pas au premier décalage. Poser l’invariant “masquer avant logger” et le rendre structurel plutôt que de compter sur ma discipline.
C’est aussi un projet qui se raconte à trois interlocuteurs. À un tech lead, j’entre par le hook et la séparation des passes. À un RSSI, j’entre par la frontière de confiance et l’invariant de journalisation. La même centaine de lignes sert les deux récits, et c’est précisément le genre de profil que je cherche à démontrer. Reste à brancher le coffre de secrets, le dashboard et le SIEM. Une version à la fois.
Code et configs : github.com/Kurgran/Homelab, dossier IA-Zone-Confiance/proxy/. Premier billet de la série « Gouvernance IA : du papier au proxy ».